cs/크롤링
[크롤링] 네이버 홈화면의 메뉴를 가져와보자
신_이나
2023. 3. 13. 16:19
! 새롭게 알게 된 점 !
보통 이런 형식으로 웹의 트리가 쌓여있다는 점 책에서 이런 것도 안알려주구 ㅠ
<html>
<div>
<ul>
<li>
<a>
<span>
- 네이버 홈화면의 메뉴를 가져와보자

여기서 초록색 부분!
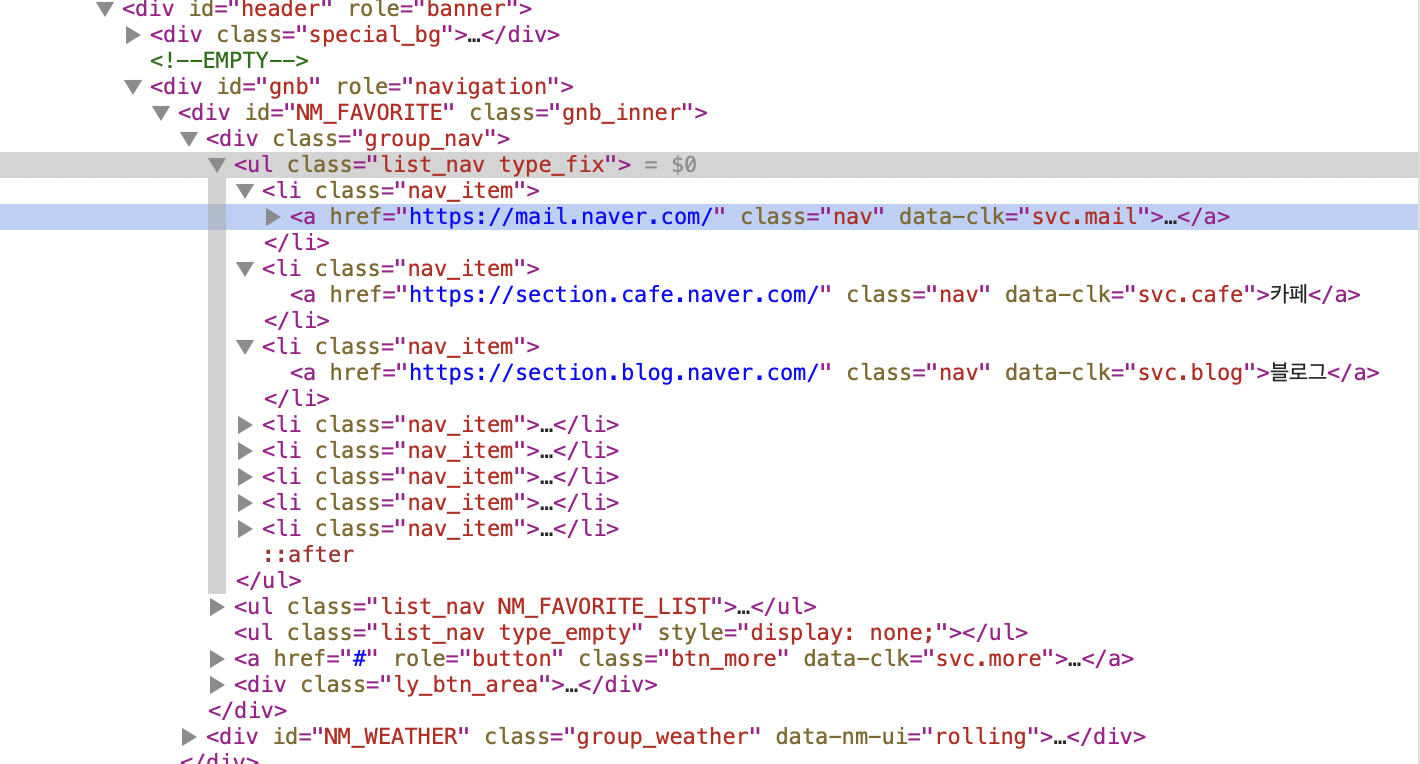
네이버의 웹소스는 이렇게 구성되어 있다. 'ul' 에서 각 'li' 들에 메뉴 이름이 쓰여있었다.
우선 'ul'에서 'li' 소스 들을 뽑아 그 안에서 a 태그들의 text 를 뽑아주도록 하겠다.
<완성 코드>
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://www.naver.com')
bs = BeautifulSoup(html, 'html.parser')
ul = bs.find('ul',{'class' : 'list_nav'})
#print(ul)
lis = ul.findAll('li')
#print(lis)
for li in lis:
a_tag=li.find('a')
print(a_tag.text)
ul = bs.find('ul',{'class' : 'list_nav'})
#print(ul)
=> ul을 찾아주는 코드
lis = ul.findAll('li')
#print(lis)
=> ul 안에 li 들을 lis 안에 저장해주었다.
for li in lis:
a_tag=li.find('a')
print(a_tag.text)
=> lis 안 li 들을 하나 하나 뽑으며 a태그의 text 를 출력하였다.
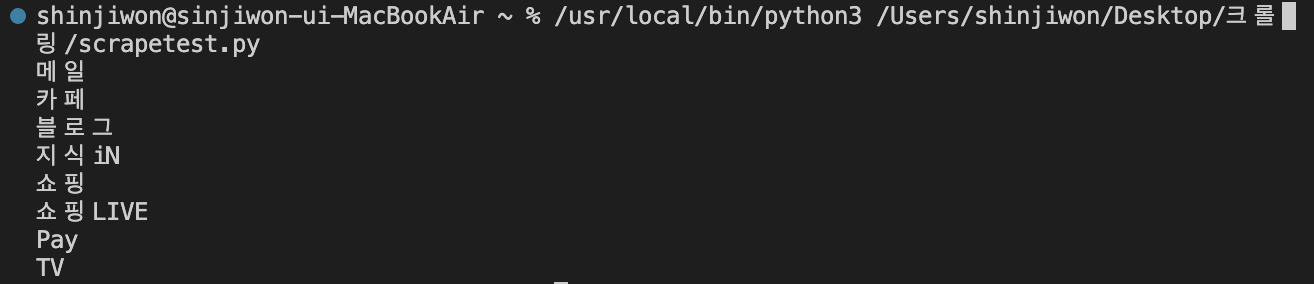
<결과>